






Nov 30, 2015
D2iQ
D2iQ
8 min read
This post was written by Max Neunhöffer of ArangoDB.
In this blog post, we explain how an ArangoDB cluster with 640 virtual CPUs can sustain a write load of 1.1 million JSON documents per second, which amounts to approximately 1GB of data per second. It takes a single short command and a few minutes to deploy this system, running on 80 nodes, using the Mesosphere Datacenter Operating System (DCOS).
Introduction
This blog post is an abridged version of our whitepaper, which contains all the results and details of the setup. The purpose of this work is to show that an ArangoDB cluster scales out well when used as a distributed document (JSON) store. It complements the benchmark series here, which looked into the performance of a single instance of ArangoDB as a multi-model database, comparing it with pure document stores, graph databases and other multi-model solutions.
"Scaling out well" means two things: (1) linear growth of performance and (2) ease of deployment and operational convenience. We achieve the latter by being the first and, so far, only operational database that is fully certified for the Mesosphere DCOS.
We would like to put the experiments at hand into a slightly broader context. In the age of polyglot persistence, software architects carefully devise their microservice-based designs around different data models like key/value, documents or graphs, considering the different scalability capabilities. With ArangoDB's native multi-model approach, they can deploy a tailor-made cluster, or single-instance, of ArangoDB for each microservice.
In this context, it is important to emphasize that the multi-model idea does not imply a monolithic design! To the contrary, some services might require a large document-store cluster, while others might employ a single-server graph database with asynchronous replicas and a load balancer for reads. Even services using a mixture of data models are easily possible.
The multi-model approach avoids the additional operational complexity of using and deploying multiple different data stores in a single project. One can use a single uniform query language across all instances and data models, and has the additional option to combine multiple data models within a single service.
We have published all test code at https://github.com/ArangoDB/1mDocsPerSec.
Test setup
To simulate such a high load, we use a special-purpose C++ program that performs the HTTP/REST requests and does the statistical analysis. We start multiple instances of this client on several machines to produce a large amount of traffic. We test read-only, write-only and 50-50 read-write in a pseudo-random pattern. The tested loads are typical for an application dealing with single-document reads and writes. The type of use case we had in mind when we designed the benchmark was that of an application or web server that performs a large volume of requests to the database, coming from multiple instances.
The atomicity of the operations is at the (JSON) document level and ArangoDB offers either "last write wins" or "compare and swap" semantics. That is, the application uses document operations as its notion of transactions. This is a very powerful concept which uses the particular capabilities of a document store well. If one would use a distributed key/value store instead, one would have to perform about 20 times as many individual operations and put groups of 20 of them into a transaction.
We scale the database cluster from 8 instances in steps of 8 instances, up to 80 instances each with 8 virtual CPUs. At the same time, we scale the load servers from 4 instances in steps of 4 instances, up to 40 instances each with 8 virtual CPUs. That is, we use from 64 to 640 virtual CPUs for ArangoDB and another 32 to 320 virtual CPUs for the load servers.
Deployment on Mesosphere
With the new Apache Mesos framework for ArangoDB, the deployment is fantastically convenient, provided you already have a Mesos or Mesosphere DCOS cluster running. We use the DCOS command line utility, which in turn taps into the ArangoDB framework and the DCOS subcommand. Starting up an ArangoDB cluster is as simple as typing:
dcos package install --options=config.json arangodb
Apache Mesos manages the cluster resources and finds a good place to deploy the individual "tasks." If the machines in your Mesos cluster have the right sizes, then Apache Mesos will find the exact distribution you intend to use.
Deploying the load servers is another piece of cake by sending a JSON document to Apache Marathon, using curl and a single HTTP/REST POST request.
For the different cluster sizes, we use the Amazon Cloud Formation template to scale the Mesosphere cluster up or down, and then in turn deploy the ArangoDB cluster and the load servers conveniently.
The results
Here we only show the results for the pure-write load. Throughput is measured in thousands of documents per second for the whole cluster. Latency times are in milliseconds, and we give the median (50th percentile) and the 95th percentile. All graphs in a figure are aligned horizontally, such that the different values for the same cluster size appear stacked vertically. The actual absolute numbers follow in the table below the plot.
(See the section titled "Detailed results" in the whitepaper for all of the graphs, tables and further background information.)
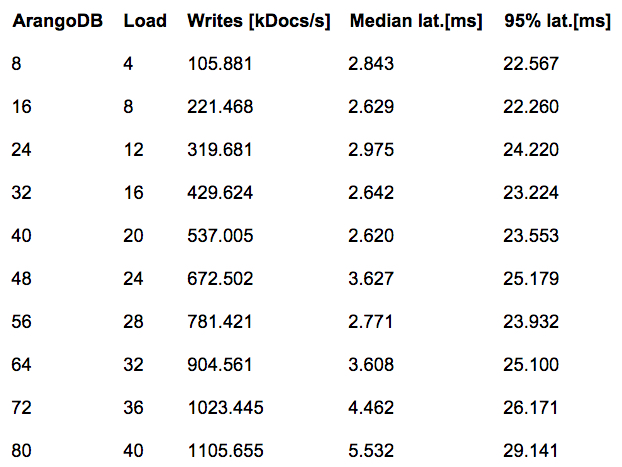
We observe very good scalability, indeed: Already with the second largest cluster size of 72 nodes, we hit our performance aim of 1,000,000 document writes per second using 576 virtual CPUs. The top is 1.1 million writes with 80 nodes and 640 virtual CPUs.
The latency is reasonable: the median is between 2 and 5 milliseconds, and the 95th percentile is still below 30 milliseconds. Looking at these latency numbers, it's clear we as developers of ArangoDB have some more homework to do in order to decrease the variance in latency.
Discussion and comparisons
For the pure write load, this means a peak total network transfer of 0.95GB per second from the load servers to the distributed database, and 140MB per second for the answers. Roughly the same amount of network transfers happens within the ArangoDB cluster for the primary storage servers, since each JSON document write has to be forwarded from the client-facing instance to the actual database server holding the data. For the asynchronous replication, this amount must be transferred another time.
The total amount of data each of the 80 ArangoDB nodes has to write to local SSD is about 46MB per second, without taking any write amplification into account. That is the reason that we use the rather expensive i2-2xlarge instance types in AWS, because only these offer enough I/O bandwidth to pull off the presented benchmark results.
Let us now consider throughput per virtual CPU and compare this to other published benchmarks from competitors. Our peak throughput performance in the largest configuration (pure write load) is around 1,730 documents per second per virtual CPU, and we keep the median latency below 5 milliseconds and the 95th percentile below 30 milliseconds.
The FoundationDB benchmark achieved 14.4 million key/value writes per second and bundled them into transactions of 20. Taking this as 720,000 write transactions per second results in about 750 write transactions per virtual CPU without any replication.
Netflix, in its Cassandra benchmark, claimed 1.1 million writes per second using Datastax's enterprise edition of Cassandra. This amounts to writing 965 documents per second per virtual CPU with a median latency of 5 milliseconds and a 95th percentile of 10 milliseconds. Google's benchmark of Cassandra uses more virtual CPUs and a replication factor of 3 with a write quorum of 2. As a consequence, it only achieves 394 documents per second per virtual CPU.
In the Couchbase benchmark, it sustained 1.1 million writes per second resulting in around 1,375 documents per second per virtual CPU, with a median latency of 15 milliseconds and a 95th percentile of 27 milliseconds.
Last but not least, the Aerospike benchmark claimed 1 million writes per second, which amounts to 2,500 documents per second per virtual CPU. Aerospike claims 83 percent of all requests took less than 16 milliseconds, and 96.5 percent of all requests took less than 32 milliseconds. Its publication does not mention any replication or disk synchronization, but claims low costs by using slow disks.
ArangoDB actually outperforms the competition considerably in the document-writes-per-virtual-CPU comparison.
Conclusion
As initially planned, this performance test only considers single-document reads and writes (that is, using the ArangoDB cluster simply as a scalable document store). Note that it is possible to add secondary indexes to the sharded collection, and for ArangoDB this means that each shard maintains a corresponding secondary index and updates it with each document write or update. This means that operations like range queries for indexed attributes will be efficient.
If the sharding is done by the primary key, then key lookups by other attributes will have to be sent to each server and will thus be less efficient. As a consequence, complicated join operations will potentially not scale well to large clusters, similar to complex graph queries, which are a fundamental challenge for large sharded graphs.
This complete benchmark test was done with the current development version of ArangoDB as of November 2015. Everything will work as already described in version 2.8, which is due to be released very soon. This release will contain the next iteration of our Mesosphere DCOS integration and will thus offer convenient setup of asynchronous replication with automatic failover.
In the first quarter of 2016, we will release version 3.0 of ArangoDB, which will contain synchronous replication and full automatic failover, as well as a lot of cluster improvements for performance, stability and convenience of scaling. It, too, will be fully integrated with the Mesosphere DCOS.
The full whitepaper with all results of the ArangoDB benchmark test is available here.


