






Jan 05, 2017
Gaston Kleiman
D2iQ

5 min read
The upcoming Mesos 1.2.0 release will ship with comprehensive health checks known as Mesos-native health checks. Strictly speaking, some health check features have been there since Mesos 0.20 and were considered experimental, but now they are stable!
Why Mesos-native? First, because it sounds cool, doesn't it? Second, because these health checks are expressed in terms of the Mesos API and performed by a Mesos executor.
This blog is a two-part series. In part one we will discuss some of the design decisions and implementation details.
In part two we will chronicle our voyage to the scaling limits of Mesos-native and Marathon health checks.
Why it matters
If an application crashes, it usually indicates that something went wrong. Mesos detects and reliably reports crashes to the frameworks. However, not all applications are designed to fail fast: they may start misbehaving while they continue running. Detecting such situations is more difficult. To address this issue, some Mesos frameworks, for example Marathon and Aurora, implemented task health checking.
Let's have a closer look at how Marathon performs an HTTP health check. A user specifies a health check in the app definition. Marathon then figures out the exact IP address and port on which a task is listening and starts periodically sending HTTP requests to it, analyzing the responses. Marathon's intuitive and straightforward approach to health checks have been in service for more than two years.
Over these two years, a few limitations came out:
- The API for health checks varies from one framework to the next and common functionality must be reimplemented with each new framework that requires health checks.
- Health checks that originate from a scheduler generate extra network traffic if the task and the scheduler are run on different nodes (this is usually the case). Moreover, network failures between the task and the scheduler, and port mapping misconfigurations might make a healthy task look unhealthy.
- Implementing health checks in the framework scheduler can become a performance bottleneck. If a framework is managing a large number of tasks, performing health checks for every task can cause scheduler performance issues, as evidenced by our scale tests.
To address these limitations we have implemented Mesos-native health checks: a unified and scalable solution.
Meet Mesos-native health checks
One of our intentions was to free framework authors from having to design their own health checking APIs. To accomplish this we updated the Mesos API, making it possible to express the definition and results of COMMAND, TCP, and HTTP(S) health checks consistently across all schedulers and executors
But a unified API is a half measure. Having to reimplement health checking functionality in all kinds of executors is tedious and may lead to slightly different implementations. To solve this we introduced a health checking library to prevent functionality fragmentation and to make the life of framework developers better.
All built-in executors support native health checks via the new API and library. Custom executors can now use the same library and API to implement health checks, regardless of whether their tasks are actual processes or something else.
One of the most helpful things that the library does is enter the appropriate task namespaces on Linux agents. This allows the health checker library to always connect to 127.0.0.1, performing the checks as close to the task as possible, and bypassing the overlay network configuration, load balancer issues, etc. This means that Mesos-native health checks are not affected by networking failures.
Since health checking is not centralized, but delegated to the agents running the tasks, the number of tasks that can be health checked can scale horizontally with the number of agents in the cluster. We prefer to show, not tell: keep reading to view the results of our scale tests.
Check out the official documentation to learn more about the design and implementation of Mesos-native health checks.
Trade-offs, caveats, and limitations
Each time a health check is run, a helper command is launched in the same agent as the task.
As we all know, nothing in life is free, so Mesos-native health checks consume extra resources on the agents; moreover, there is some overhead for fork-execing a process and entering the tasks' namespaces every time a task is checked. Check the investigation of our initial scale test results in part two of this series for more details on the impact of this overhead.
The health check processes share resources with the task that they check: don't forget to update your task definitions to account for the extra resources consumed by the health checks.
Note that there is no separate cgroup for a health check process, it shares the cgroups and resources with the task it checks. Even if extra resources are added to a task definition with health checks, there is no guarantee the health check process will get them, even with CFS enabled.
Health checks run as close to the task as possible; HTTP(S) and TCP health checks use 127.0.0.1 as target IP. As a result, health checks are not vulnerable to network glitches, but they require tasks to listen on the loopback interface in addition to whatever interface they require. If you run a service in production, you will want to make sure that the users can reach it. Mesos/Marathon health checks are not enough to ensure that your load balancer can reach the tasks, so you might also want to use load balancer health checks and monitor the load balancer metrics.
At the moment of writing this post, COMMAND checks are not supported for TaskGroups, but we expect this to change very soon.
Scale
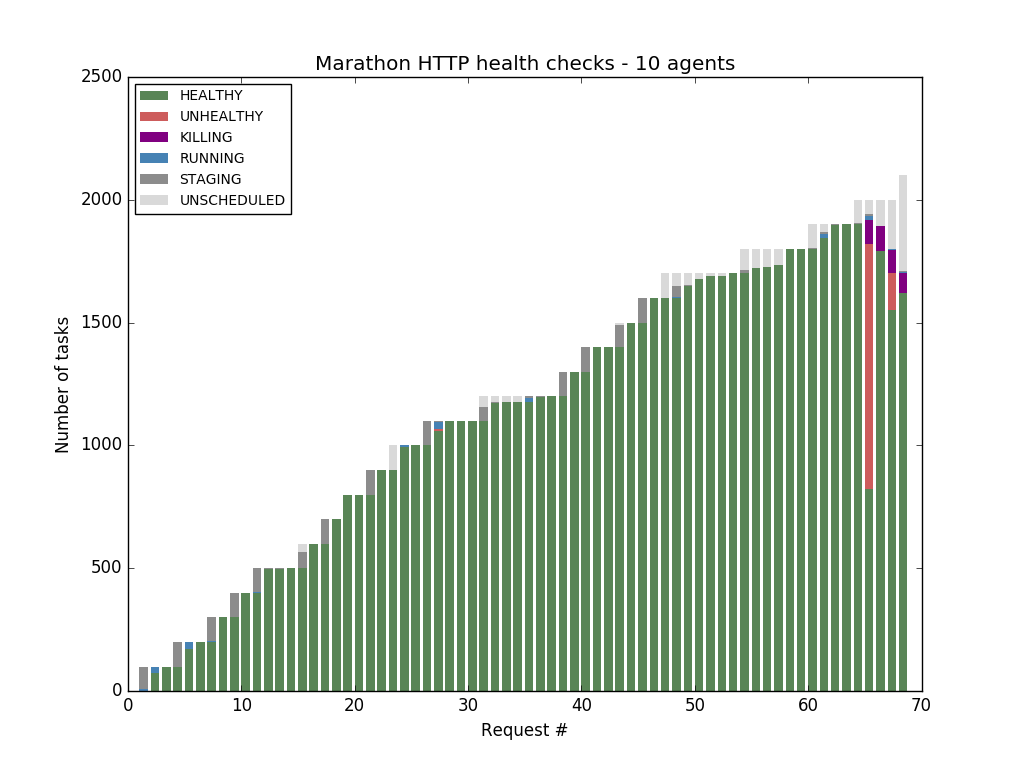
We ran some experiments, and found out that Marathon HTTP health checks start to fail after Marathon has probed more than 1900 tasks:
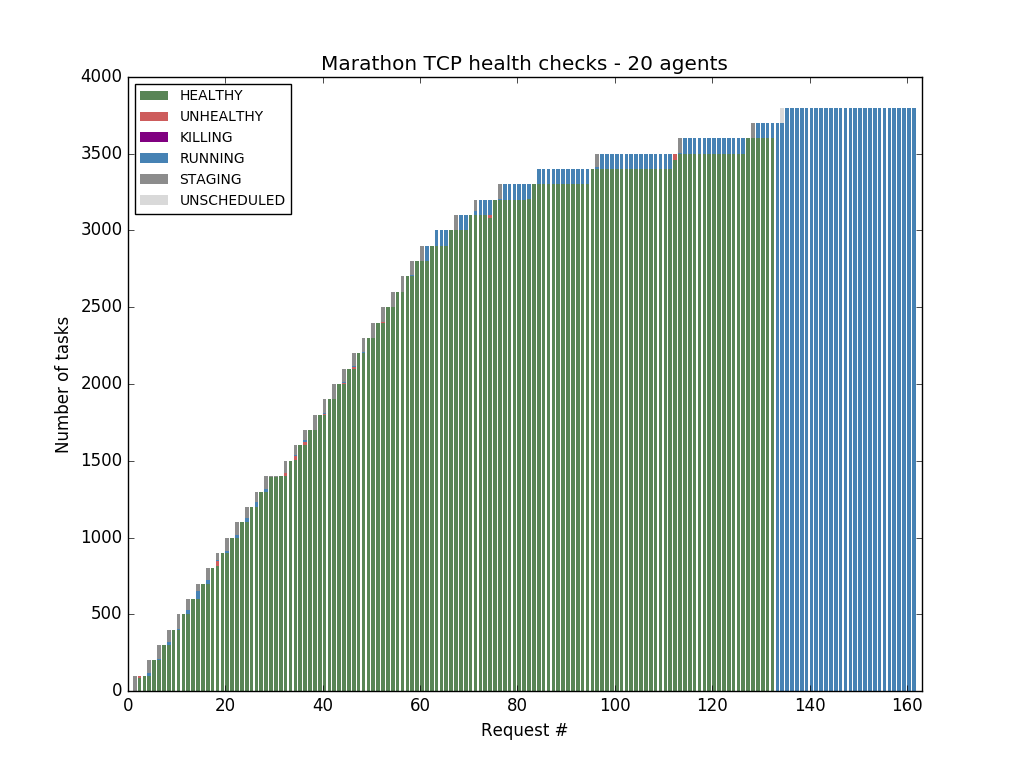
Marathon TCP health checks fare a bit better, but Marathon becomes completely unresponsive after reaching 3700 tasks:
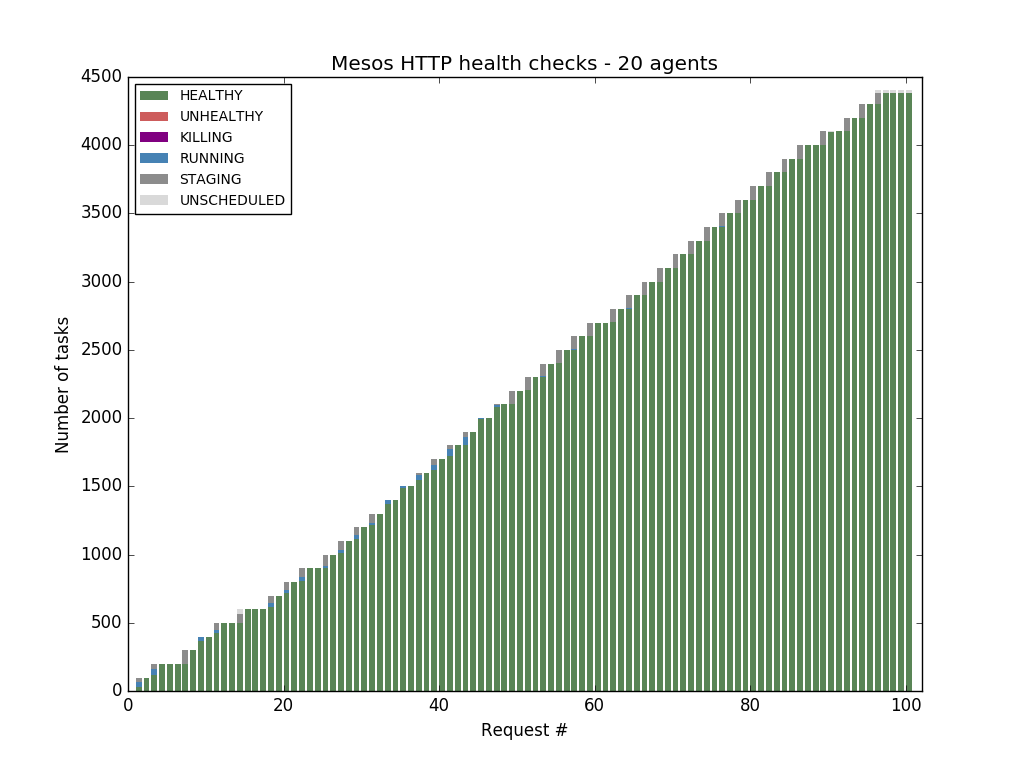
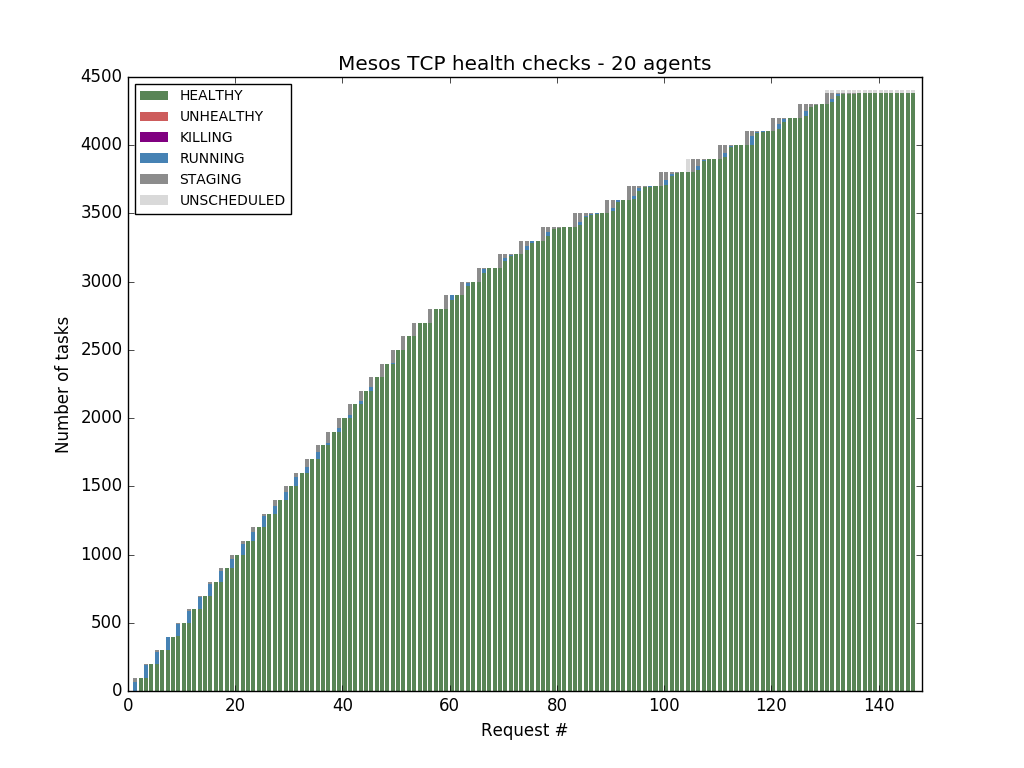
Mesos-native health checks overcome this bottleneck and scale horizontally with the number of Mesos agents.
This was just a synopsis of our voyage to the scaling limits of Mesos-native and Marathon health checks, stay tuned for the chronicle in part two.


