






Apr 25, 2017
Fernando Sanchez
D2iQ

6 min read
D2iQ has chosen to sunset DC/OS, with an end-of-life date of October 31, 2021. With D2iQ Kubernetes Platform (DKP), our customers get the same benefits provided by DC/OS and more, as well as access to the most impressive pace of innovation the technology world has ever seen.
Learn more about D2iQ Kubernetes Platform here.
This is the second part of a series on Networking for Docker containers. The first part of this series introduces the basics of container networking. In this post we will cover the Service Discovery topic and how it has evolved over time, along with the changes in computing and virtualization. The third part in the series covers different strategies for Service Discovery, Registration and Load Balancing.
These three concepts are intrinsically related, to a point that they're commonly considered to be the three pillars that answer a critical application delivery question: How can distributed applications be most efficiently and conveniently made available to consumers?
Introduction to Service Discovery
Service discovery sounds like a novel topic, but it actually has been around for a very long time. Indeed, for as long as internet applications have existed, there has always been a need for an efficient and convenient mechanism to make them available to consumers. That could be a first simplified definition for Service Discovery: the ability for application consumers to learn about the location of the devices providing those applications, initially knowing the application name.
Internet applications run on hosts that usually connect to the network through an IP address and port combination. If a consumer wants to access a web service that lives in port 80 on a host with IP address 52.35.5.25, she could simply enter in her web browser something like http://52.35.5.25:80 and she'd get to the service. But it's more convenient for users to use names for services instead of IP addresses as names are much easier to remember. Also, IP addresses in servers may change over time. In order to translate complicated addresses to convenient names we use the Domain Name Service (DNS), so we could consider DNS a very early form of service discovery.
If applications lived on a single host, DNS might have been sufficient for many use cases. But as we know, internet applications require far more horsepower than a single host can provide. So we spread applications across many hosts, each one with a different IP address. Traffic coming from users will typically be balanced across the many hosts delivering the application. In order for the user to still be able to use a single endpoint towards the application (like the one our DNS entry points to), and then have that request automatically redirected to one of the active application's endpoints, we typically use a device (or software program) called Load Balancer.
Load Balancers, Service Discovery and Service Registration
The Load Balancer offers a "virtual IP" facing the customers, where it receives traffic directed to the service. It also keeps a list of the service "backends" (i.e. the servers actually hosting the application) with their IP address and port location. Finally, many Load Balancers usually keep "health testing" each one of the backends to ensure they respond to requests correctly. In case they fail to respond adequately, the Load Balancer will typically stop sending traffic to the failed endpoint and remove it from the list of backends for that application. Finally, the Load Balancer will decide which backend to send each individual request to, thus allowing for different traffic distribution strategies (round-robin, least number of connections, lower CPU load, etc.).
You may be wondering "how does the Load Balancer learn where the backends are? And how does it get updated when we add a new backend to increase our application's capacity?" Well, the list of backends is generally part of the Load Balancer's configuration, and some years ago this configuration was entered manually. A network administrator would log into the load balancer and manually create the configuration defining the Application, the Virtual IP, and the list of endpoints. If a new endpoint had to be added, the operator would log in again and add the corresponding configuration. In today's terminology, the network admin was manually "registering" the endpoints delivering the service.
This could be considered a simplified version of what we know as "Service Registration": the process by which an application backend is added to the list, so that it can be made available to consumers that only need to be aware of the Virtual IP or name. In this case, service registration is performed manually by the operator.
Service Discovery and Registration in Tiered Architectures
So far, we've mostly assumed that the Load Balancer is connecting "external" users to our front facing applications. But usually applications are composed of several "Tiers" or layers. As an example, since the late nineties many applications have been designed with three tiers: a frontend or "web" tier that presents the visual web interface to the end user, an "application" tier where the application logic resides and most of the processing is done, and a "database" tier that holds the data that the application needs to run. The "web" tier communicates with the "app" tier in order to get the information that will be displayed to the user. The "app" tier contacts the "DB" tier to find the stored information on which to perform the operations. Each one of these tiers presents the same issue: it is likely implemented with many individual instances, and it is not practical or even feasible to assume that the consumers of the service can constantly update themselves to adapt to changes in individual backend list.
For example, it wouldn't be practical or even feasible to have our web frontend maintaining a list of IP addresses and port numbers where the application is sitting. Instead, it's advisable to have our web frontend simply contact something like "myapplication.mydomain", then have a DNS service resolve that to the virtual IP hosted by our "Load Balancer" and finally let the Load Balancer steer the traffic to one of the backends.
How Virtualization Changed Service Registration
These solutions were conceived when most of the workloads were running directly on physical servers. But in order to increase hardware usage, and to make provisioning more agile, server virtualization was introduced in the early 2000s allowing for many "virtual servers" to be running in a single physical server.
This allows for more automation on the application side as virtual servers are easier to handle programmatically, and hence Orchestration platforms have been introduced to automatically control the creation, deletion and modification of applications and their backends. But that also means that manually configuring a load balancer every time this happens is not an acceptable solution anymore given the frequency at which the backend list changes. The maintenance of an updated "backend list" in the load balancer needs to be fully automated. It also needs to be directly updated as backends are created, destroyed or modified.
In order to do so, several service registration strategies have been proposed and successfully implemented, as we will discuss in detail in an upcoming blog post.
How containerization changed service registration
Containers provide an excellent way for developers to deliver applications to production that are self-contained and include all their dependencies, thus dramatically reducing integration, testing and dependency issues. Also, containers can be created and destroyed in seconds, which increases the application's ability to dynamically scale up and down adapting to demand changes, and to react upon failures. Finally, containers are usually very lightweight and provide increased density per physical server.
As opposed to physical or virtual servers, containers are also usually designed to be ephemeral in nature. For example, containers that exceed a threshold of memory consumption are routinely rebooted, or relocated to different physical servers. They're basically designed to be "cattle" and not "pets" (as defined by Randy Bias in his impactful talk "Architectures for Open and Scalable Clouds"). This means that we shouldn't really have to care about each individual container staying alive, but rather rely on a system that makes our application self-healing by automatically detecting failures in individual containers and being able to reboot failed ones to maintain our "target state". We will define "how many containers" our application needs (the "target state"), but each individual container should be replaceable in case of failure.
A service designed this way is available through the virtual IP (or name), but individual containers would routinely be rebooted, destroyed or relocated, and the task of keeping an updated list of Application backends at every point in time must be fully automated.
Service Registration is Key in Microservices Architecture
This pattern is made even more relevant when applications are migrated towards a Microservices architecture. This not a post covering microservices in detail, but in order to understand how service registration and load balancing affect a microservices architecture, we can use a simplified approach to the microservices concept: by adopting a microservices approach we "break down" our applications into individual smaller pieces. These smaller pieces would become autonomous processes (or "mini-applications"), thus enabling to scale each one more granularly, making them easier to debug, and providing flexibility about how each piece is developed. This means that the different pieces of our application will not live in the same process (and possibly, not even in the same host), so they will not communicate with each other through internal memory addresses but rather through REST APIs across the network.
This leads to an even bigger dependency on an efficient and easy-to-use Service Discovery mechanism, so that developers writing each piece of the system (each microservice) can easily find other pieces they need to send requests to through well-known Virtual IPs or names.
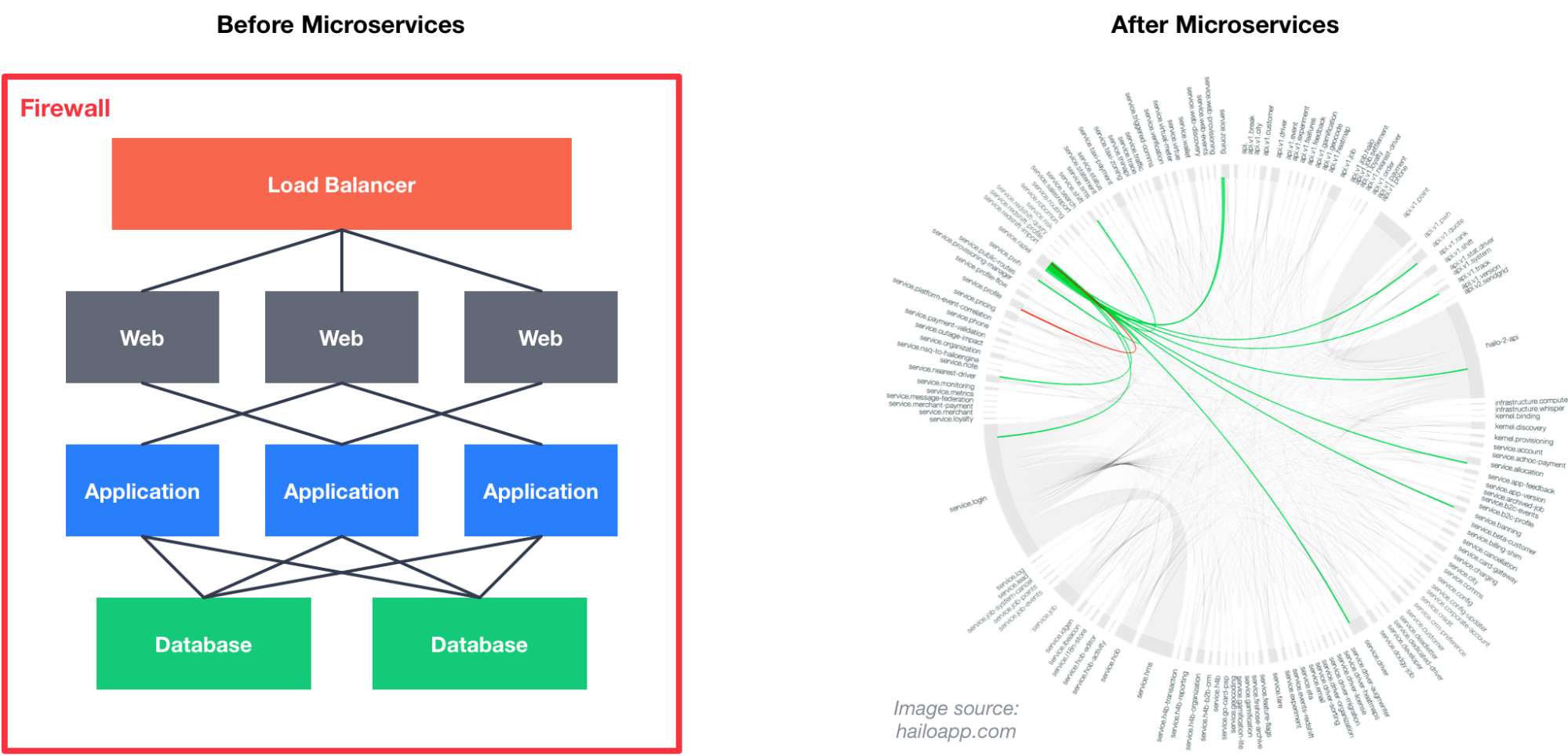
The picture below illustrates the traffic patterns between different microservices forming a customer's web-scale application. Each entry at the edge of the circle represents a microservice, and the thickness of the line between entries represents volume of traffic between them. It should help understand as to how important providing an efficient service discovery mechanism is to today's web-scale applications.
Hopefully this post has been helpful to illustrate the Service Discovery topic, how it has evolved along the years, and how the different software architectures along the years have made the requirement for an efficient Service Discovery and Load Balancing solution even more prominent.
References
- Michael Hausenblas: "Docker Networking and Service Discovery" (eBook)
- Fernando Sanchez, Fawad Khaliq: "Service Discovery and Microservices in a Microservices Architecture" (Presentation at OpenStack summit Barcelona 2016)
- Randy Bias: Architectures for Open and Scalable Clouds (Presentation at CloudConnect 2012)


