






Sep 06, 2017
Amr Abdelrazik
D2iQ

6 min read
Companies like Twitter, Apple, Netflix, Uber, and Yelp have disrupted countless businesses with their ability to deliver personalized, real-time experiences to customers at massive scale. And mainstream enterprises need to develop these features customers now take for granted if they are to survive and thrive.
To build the modern data-rich applications required to compete today -- from IoT, to connected cars, to AI and machine learning -- development and operations teams are adopting a new generation of platform services and methodologies including containers, microservices, DevOps, CI/CD, and a plethora of new big data and fast data tools.
This pattern forms the foundation of cloud-native architectures, and is distributed in nature. Running these distributed systems is not easy, leading many companies to turn to cloud providers like AWS. But while public clouds can hide some of the complexities, they can also lead to skyrocketing costs, loss of control of your data, and architectural lock-in.
Many leading businesses are using modern datacenter cluster managers to run modern data-rich applications to simplify adoption, reduce risk and maintain architectural control. In this blog we will explain how Apache Mesos, a modern datacenter cluster manager, came to be, define application-aware scheduling, and explain why it is becoming increasingly critical to mainstream enterprises.
The Modern Enterprise Architecture Challenge
Before the world moved to distributed applications, adopting new software technologies meant installing software on traditional x86 infrastructure. Whether it was an e-commerce platform, middleware, or first-generation business intelligence tool, we were installing monolithic software components on either virtual or physical machines. This all changed with today's distributed cloud-native technologies.
The last few years have seen an explosion of new open source technologies, mostly from early webscale companies solving specific problems. The most popular examples include Apache Hadoop from Yahoo, Apache Kafka from LinkedIn, and Apache Cassandra from Facebook. These technologies have provided a way for businesses to build new services with proven technologies instead of building from scratch. A common characteristic of these technologies is their reliance on a distributed architecture to provide resilience, performance and scalability. Enterprises have no choice but to adopt these technologies to stay competitive.
To manage these technologies, Google and Facebook developed datacenter-scale operating models with proprietary cluster managers. Without the massive R&D budgets of Google and Facebook, mainstream enterprises continued to use traditional machine-centric architectures, leading to siloed, complex operations and failed implementations.
This all changed when Apache Mesos was published at UC Berkeley AMPLab. Taking lessons from first generation monolithic cluster managers like Google's Borg and Facebook's Tupperware, Mesos introduced a modular architecture with application-aware scheduling to accommodate a broad variety of distributed workloads. Application-aware scheduling allows each service to automate much of the service-specific operational logic while maintaining complete isolation, resulting in reduced administrative overhead, increased uptime, and increased ability to easily accommodate new workloads. Mesos's flexibility led to its quick adoption by Twitter, Apple(Siri), Yelp, Uber, and Netflix, and allowed many other organizations to run a combination of microservices and data services together such as the SMACK stack Architecture.
How Application-Aware Scheduling Works
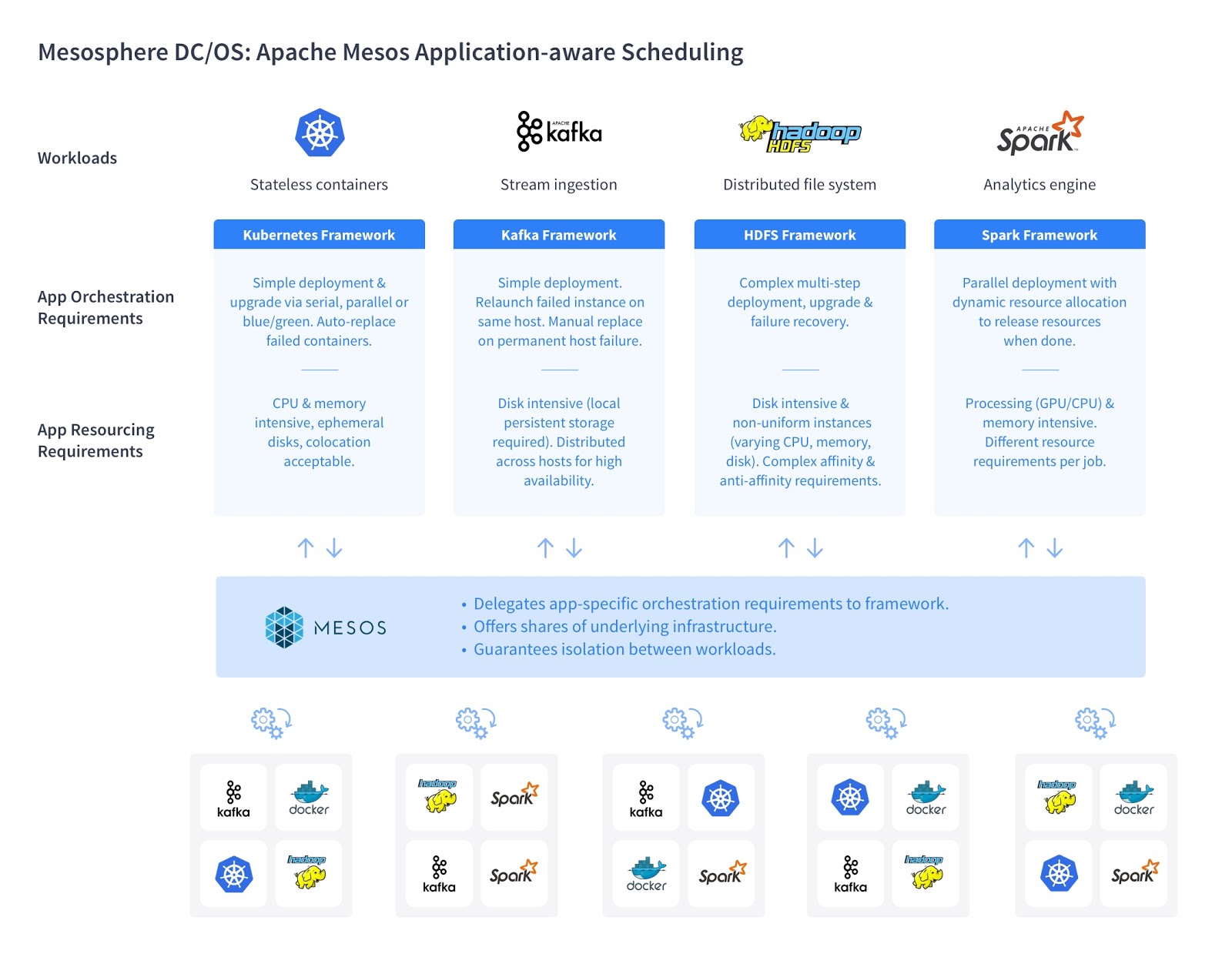
Application-aware scheduling works by encapsulating the application-specific operational logic in a Mesos framework (analogous to a runbook in operations). An operator using Apache Mesos or Mesosphere DC/OS (An Apache Mesos Distribution) doesn't need to worry about the intricate details of each service in order to successfully operate it. With a single click, he can be sure that the service will be deployed according to best practices every time, on any infrastructure whether it's baremetal, private or public cloud. The framework also understands the best way to automatically detect and recover the service from failure or the proper procedure for scaling it.
Mesos frameworks are also completely isolated from each other, which means that enterprises can have multiple, independently managed, instances of the technology on the same infrastructure. Operators can operate, scale and upgrade each instance independently from each other, providing complete flexibility to application teams using the technology, while maintaining maximum utilization and efficiency.
The modular architecture of application-aware scheduling gives Mesos the unique ability to individually manage a diverse set of workloads. This includes traditional applications such as Java, stateless Docker microservices, real-time analytics, stateful distributed data services, and modern machine learning and AI tools. Without application-aware scheduling, adopting new technologies would always require significant investment in time and resources. For each new technology, enterprises need to hire, onboard and retain the right expertise; plan, procure and operationalize new hardware capacity; manually troubleshoot and recover from failures; plan for scaling, upgrade and update configurations.
How Application-Aware Scheduling Accelerates New Technology Adoption with Less Risk
Application-aware scheduling removes many of the risks associated with adopting new technologies. Organization can realize the following benefits:
- Maximize Infrastructure Efficiency and Utilization: Mesos can pool different workloads on the same platform while still maintaining resource guarantees and isolation. The result is higher utilization and cost savings for on-premise or cloud-based infrastructure.
- Reduce Administration Overhead with Automation: Mesos application-aware scheduling automates common operational tasks, simplifying operations, increasing uptime and reducing human error, to provide a consistent public cloud experience on any physical, virtual or cloud infrastructure.
- Add New Services without Adding New Expertise: Mesos's modular architecture allows adding or updating existing services independently from each other. This makes Mesos an evergreen platform that can easily be extended to future workloads. Mesosphere DC/OS already includes more than 100 services in the DC/OS catalog and more are coming every day.
- Dramatically Improve Resilience and Uptime: The Mesos architecture separates the application-level scheduler from the underlying resource management. This results in a resilient platform for mission critical workloads that can scale from tens to tens of thousands of nodes.
- Achieve Hybrid Cloud Portability: Mesos abstracts the underlying infrastructure whether it's physical, virtual or public cloud, allowing organizations to easily run and migrate any application across any cloud without fear of lock-in.
Example: Application-aware Scheduling Simplifies Apache Cassandra Deployments
Cassandra is a database that provides the flexibility of NoSQL and enables massive read and write performance, all while running on commodity server hardware. For a company to consider using Cassandra in one of their applications, the operations team needs to understand how to:
- Deploy Cassandra in a reliable and secure manner.
- Properly size it for optimum performance.
- Scale it as demand increases.
- Troubleshoot issues as they arise.
- Upgrade it when a new version comes to the market.
Let's take one of the above tasks, upgrades, in a traditional VM or physical infrastructure. Upgrading Cassandra requires:
- Planning maintenance windows.
- Taking a backup of all data.
- Logging on to each node and taking the node offline one at a time.
- Performing the upgrade in-place in a specific sequence.
- Executing special checks and commands on each node before and after the upgrade.
- In case of upgrade failure, the operations team needs to plan for a roll-back procedure that might even be more complex than the upgrade plan itself. Many organizations go so far as to have operators build and maintain a dedicated standby cluster for mission-critical applications.
In contrast, with Mesos application-aware scheduling, deploying and even upgrading Cassandra is accomplished using a single command. The operator chooses from all the upgradeable versions available from the DC/OS catalog. Within minutes all instances are upgraded to the newest release, using the correct sequences, commands and checks, without downtime. If something goes wrong for any reason, an operator can immediately roll back to the previous version without losing data.
Adopting Cassandra (or any of the dozens of new fast data tools in demand by applications teams today) can be a massive project -- requiring a new set of knowledge and skills and weeks or months of effort.
Mesos Application-aware scheduling can transform how quickly enterprises can adopt and operationalize new technologies. With new tools and latest technologies, IT organizations can help application developers and data scientists be more and more productive, creating a competitive advantage and delighting customers.
It's now easier than ever to experience the true power of Mesos with Mesosphere DC/OS, so check it out.


