






Jul 31, 2017
Amr Abdelrazik
D2iQ

10 min read
Editorial Comment: we hope this old blog is still providing some value, even in a very different world than the one in which it was written. To find out more about the D2iQ Kubernetes platform, look here.
Editorial note: what follows was written several years ago, in what amounts to a different world. That said, there is still a lot of wisdom here that holds up. Rather than rewrite or replace it, we’ll just insert some editorial commentary to reflect the current market and technology environments. These comments will be in italics, just like this paragraph, so you can easily spot the new stuff. --AA
There are countless articles, discussions, and lots of social chatter comparing Docker, Kubernetes, and Mesos. If you listen to the partially-informed, you'd think that the three open source projects are in a fight-to-the death for container supremacy. You'd also believe that picking one over the other is almost a religious choice; with true believers espousing their faith and burning heretics who would dare to consider an alternative.
That's all bunk.
While all three technologies make it possible to use containers to deploy, manage, and scale applications, in reality they each solve for different things and are rooted in very different contexts. In fact, none of these three widely adopted toolchains is completely like the others.
Instead of comparing the overlapping features of these fast-evolving technologies, let's revisit each project's original mission, architectures, and how they can complement and interact with each other.
Let's start with Docker...
Docker Inc., today started as a Platform-as-a-Service startup named dotCloud. The dotCloud team found that managing dependencies and binaries across many applications and customers required significant effort. So they combined some of the capabilities of Linux cgroups and namespaces into a single and easy to use package so that applications can consistently run on any infrastructure. This package is the Docker image, which provides the following capabilities:
- Packages the application and the libraries in a single package (the Docker Image), so applications can consistently be deployed across many environments;
- Provides Git-like semantics, such as "docker push", "docker commit" to make it easy for application developers to quickly adopt the new technology and incorporate it in their existing workflows;
- Define Docker images as immutable layers, enabling immutable infrastructure. Committed changes are stored as an individual read-only layers, making it easy to re-use images and track changes. Layers also save disk space and network traffic by only transporting the updates instead of entire images;
- Run Docker containers by instantiating the immutable image with a writable layer that can temporarily store runtime changes, making it easy to deploy and scale multiple instances of the applications quickly.
Docker grew in popularity, and developers started to move from running containers on their laptops to running them in production. Additional tooling was needed to coordinate these containers across multiple machines, known as container orchestration. Interestingly, one of the first container orchestrators that supported Docker images (June 2014) was Marathon on Apache Mesos (which we'll describe in more detail below). That year, Solomon Hykes, founder and CTO of Docker, recommended Mesos as "the gold standard for production clusters". Soon after, many container orchestration technologies in addition to Marathon on Mesos emerged: Nomad, Kubernetes and, not surprisingly, Docker Swarm (now part of Docker Engine).
As Docker moved to commercialize the open source file format, the company also started introducing tools to complement the core Docker file format and runtime engine, including:
- Docker hub for public storage of Docker images;
- Docker registry for storing it on-premise;
- Docker cloud, a managed service for building and running containers;
- Docker datacenter as a commercial offering embodying many Docker technologies.
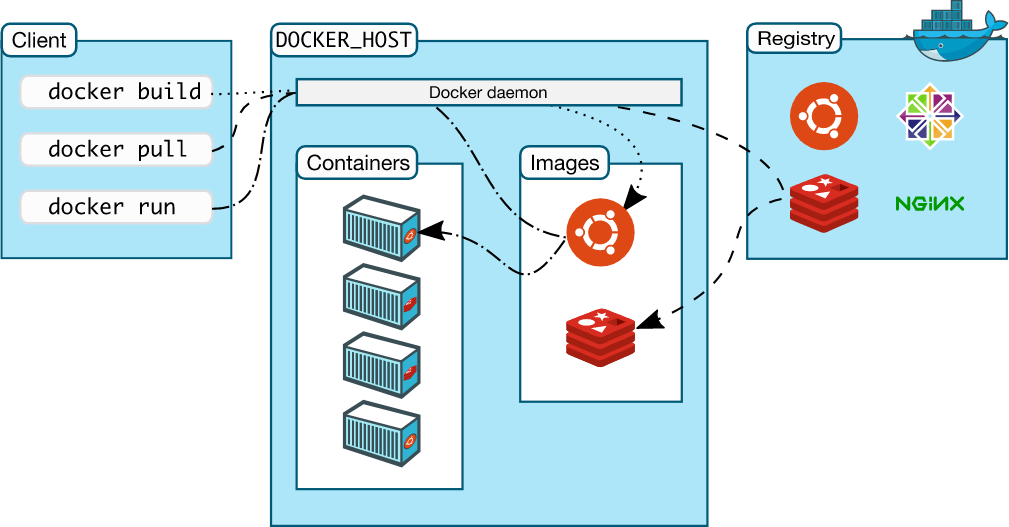
Source: www.docker.com
Docker's insight to encapsulate software and its dependencies in a single package have been a game changer for the software industry; the same way mp3's helped to reshape the music industry. The Docker file format became the industry standard, and leading container technology vendors (including Docker, Google, Pivotal, Mesosphere and many others) formed the Cloud Native Computing Foundation (CNCF) and Open Container Initiative (OCI). Today, CNCF and OCI aim to ensure interoperability and standardized interfaces across container technologies and ensure that any Docker container, built using any tools, can run on any runtime or infrastructure.
Here in 2021, we have seen the Docker file standard persist as the market leader for containerization. Meanwhile, Docker’s broader ambitions did not play out as the company had hoped and the company was split in late 2019. Mirantis acquired Docker’s enterprise business and team, including Docker Enterprise Engine, Docker Trusted Registry, Docker Unified Control Plane and Docker CLI. The remaining Docker core “ . . . is ushering in a new era with a return to our roots by focusing on advancing developers’ workflows when building, sharing and running modern applications.”
Enter Kubernetes
Google recognized the potential of the Docker image early on and sought to deliver container orchestration "as-a-service" on the Google Cloud Platform. Google had tremendous experience with containers (they introduced cgroups in Linux) but existing internal container and distributed computing tools like Borg were directly coupled to their infrastructure. So, instead of using any code from their existing systems, Google designed Kubernetes from scratch to orchestrate Docker containers. Kubernetes was released in February 2015 with the following goals and considerations:
- Empower application developers with a powerful tool for Docker container orchestration without having to interact with the underlying infrastructure;
- Provide standard deployment interface and primitives for a consistent app deployment experience and APIs across clouds;
- Build on a Modular API core that allows vendors to integrate systems around the core Kubernetes technology.
By March 2016, Google donated Kubernetes to CNCF, and remains today the lead contributor to the project (followed by Redhat, CoreOS and others).
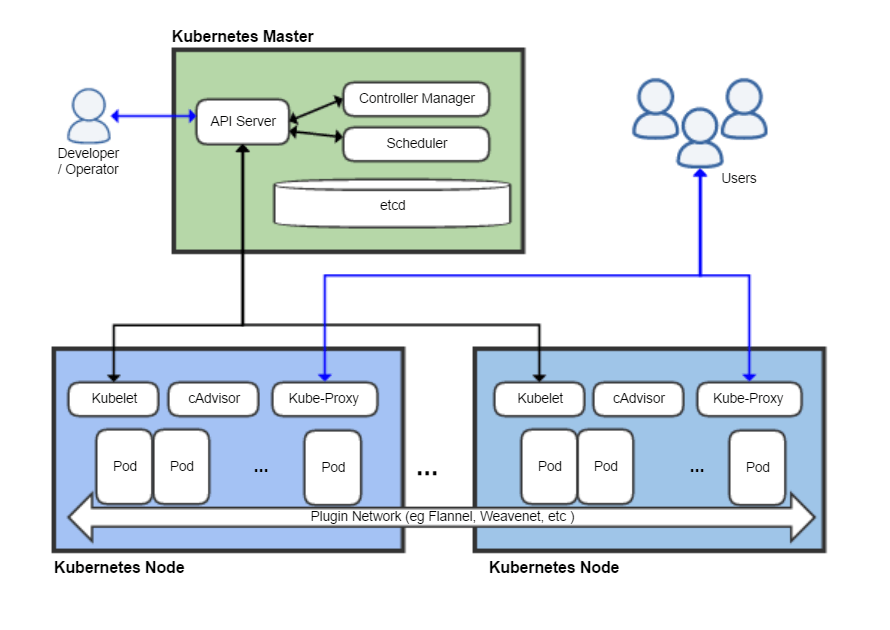
Source: wikipedia
Kubernetes was very attractive for application developers, as it reduced their dependency on infrastructure and operations teams. Vendors also liked Kubernetes because it provided an easy way to embrace the container movement and provide a commercial solution to the operational challenges of running your own Kubernetes deployment (which remains a non-trivial exercise). Kubernetes is also attractive because it is open source under the CNCF, in contrast to Docker Swarm which, though open source, is tightly controlled by Docker, Inc.
Kubernetes' core strength is providing application developers powerful tools for orchestrating stateless Docker containers. While there are multiple initiatives to expand the scope of the project to more workloads (like analytics and stateful data services), these initiatives are still in very early phases and it remains to be seen how successful they may be.
Well, things have certainly changed here. The “multiple initiatives” mentioned above have evolved into a complex ecosystem of projects enabling a full range of enterprise workloads. While it takes the right combination of technology and expertise to actually operate Kubernetes in production at scale, Kubernetes has become the default cloud native application infrastructure platform. Statistics for the percentage of enterprises running Kubernetes range from about 90% per the CNCF (which may reflect some sample bias, as they are surveying their membership and those entities that are member-adjacent) to a low of about 30% from some of the major IT analyst firms (which may reflect a different kind of sample bias). Whatever the real number, it is substantial and growing extremely rapidly. It’s fair to say that as of 2021, Kubernetes has won the argument posited at the beginning of this blog and that Kubernetes has, through its rapid, continuous, and ongoing development, subsumed Docker and encroached on terrain that Mesos once had sole control over. More on this last point below.
Apache Mesos
Apache Mesos started as a UC Berkeley project to create a next-generation cluster manager, and apply the lessons learned from cloud-scale, distributed computing infrastructures such as Google's Borg and Facebook's Tupperware. While Borg and Tupperware had a monolithic architecture and were closed-source proprietary technologies tied to physical infrastructure, Mesos introduced a modular architecture, an open source development approach, and was designed to be completely independent from the underlying infrastructure. Mesos was quickly adopted by Twitter, Apple(Siri), Yelp, Uber, Netflix, and many leading technology companies to support everything from microservices, big data and real time analytics, to elastic scaling.
As a cluster manager, Mesos was architected to solve for a very different set of challenges:
- Abstract data center resources into a single pool to simplify resource allocation while providing a consistent application and operational experience across private or public clouds;
- Colocate diverse workloads on the same infrastructure such analytics, stateless microservices, distributed data services and traditional apps to improve utilization and reduce cost and footprint;
- Automate day-two operations for application-specific tasks such as deployment, self healing, scaling, and upgrades; providing a highly available fault tolerant infrastructure;
- Provide evergreen extensibility to run new application and technologies without modifying the cluster manager or any of the existing applications built on top of it;
- Elastically scale the application and the underlying infrastructure from a handful, to tens, to tens of thousands of nodes.
Mesos has a unique ability to individually manage a diverse set of workloads -- including traditional applications such as Java, stateless Docker microservices, batch jobs, real-time analytics, and stateful distributed data services. Mesos' broad workload coverage comes from its two-level architecture, which enables "application-aware" scheduling. Application-aware scheduling is accomplished by encapsulating the application-specific operational logic in a "Mesos framework" (analogous to a runbook in operations). Mesos Master, the resource manager, then offers these frameworks fractions of the underlying infrastructure while maintaining isolation. This approach allows each workload to have its own purpose-built application scheduler that understands its specific operational requirements for deployment, scaling and upgrade. Application schedulers are also independently developed, managed and updated, allowing Mesos to be highly extensible and support new workloads or add more operational capabilities over time.
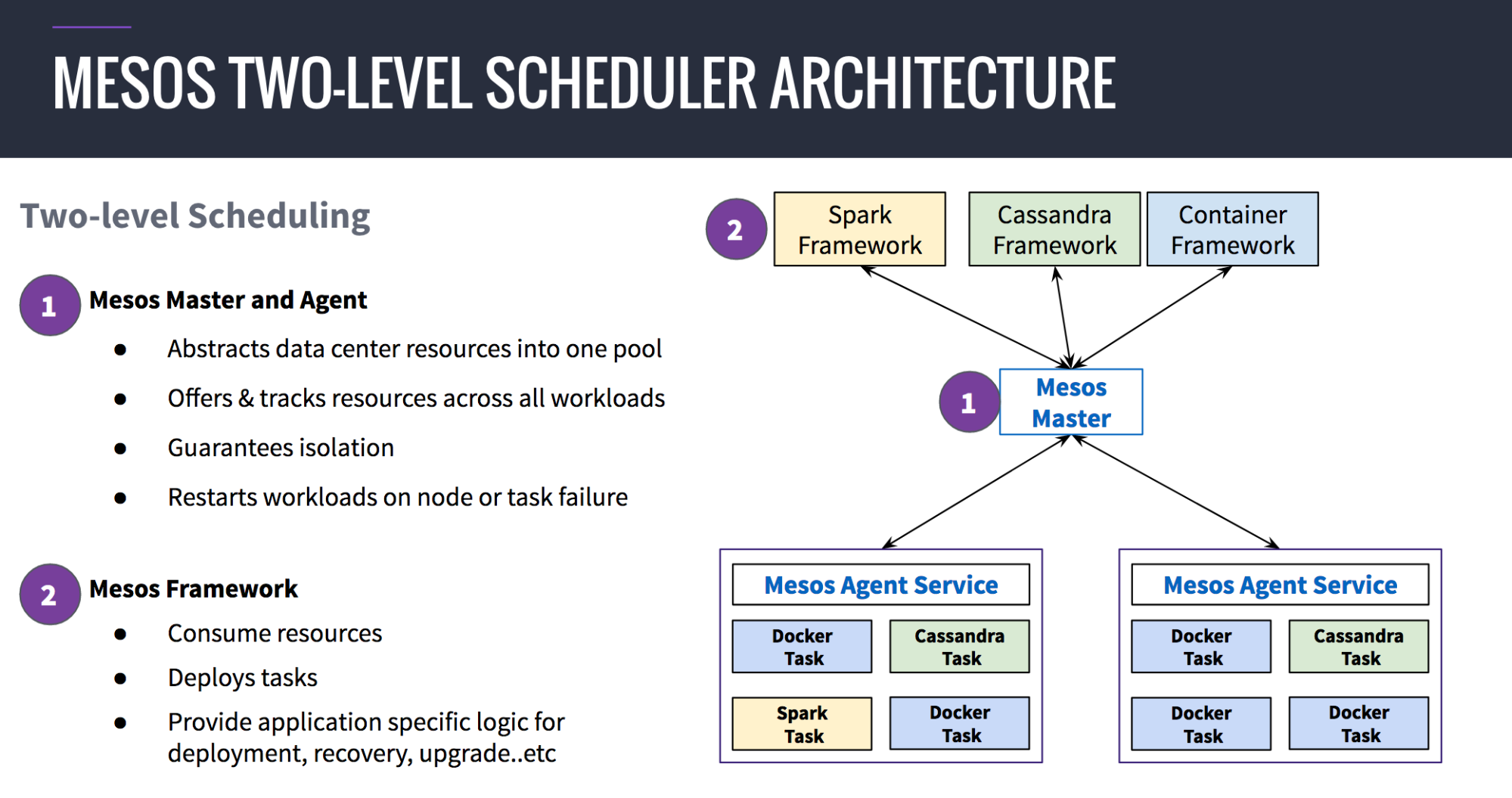
Take, for example, how a team manages upgrades. Stateless application can benefit from a "blue/green" deployment approach; where another complete version of the app is spun up while the old one is still live, and traffic switches to the new app when ready and the old app is destroyed. But upgrading a data workload like HDFS or Cassandra requires taking the nodes offline one at a time, preserving local data volumes to avoid data loss, performing the upgrade in-place with a specific sequence, and executing special checks and commands on each node type before and after the upgrade. Any of these steps are app or service specific, and may even be version specific. This makes it incredibly challenging to manage data services with a conventional container orchestration scheduler.
Mesos' ability to manage each workload the way it wants to be treated has led many companies to use Mesos as a single unified platform to run a combination of microservices and data services together. A common reference architecture for running data-intensive applications is the "SMACK stack".
A Moment of Clarity
Notice that we haven't said anything about container orchestration to describe Apache Mesos. So why do people automatically associate Mesos with container orchestration? Container orchestration is one example of a workload that can run on Mesos' modular architecture, and it's done using a specialized orchestration "framework" built on top of Mesos called Marathon. Marathon was originally developed to orchestrate app archives (like JARs, tarballs, ZIP files) in cgroup containers, and was one of the first container orchestrators to support Docker containers in 2014.
So when people compare Docker and Kubernetes to Mesos, they are actually comparing Kubernetes and Docker Swarm to Marathon running on Mesos.
Why does this matter? Because Mesos frankly doesn't care what's running on top of it. Mesos can elastically provide cluster services for Java application servers, Docker container orchestration, Jenkins CI Jobs, Apache Spark analytics, Apache Kafka streaming, and more on shared infrastructure. Mesos could even run Kubernetes or other container orchestrators, though a public integration is not yet available.
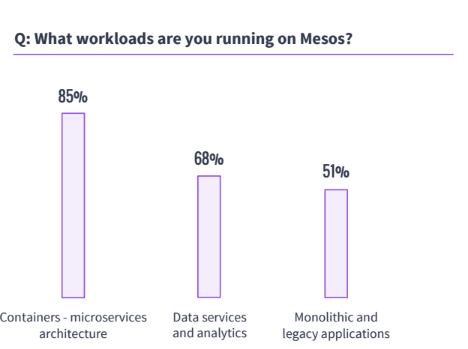
Source: Apache Mesos Survey 2016
Another consideration for Mesos (and why it's attractive for many enterprise architects) is its maturity in running mission critical workloads. Mesos has been in large scale production (tens of thousands of servers) for more than 7 years, which is why it's known to be more production ready and reliable at scale than many other container-enabling technologies in the market.
Mesos (and its derivative, DC/OS) remain extraordinarily powerful and capable technologies. However, Kubernetes has to a very large degree caught up with Mesos in terms of its capabilities and ability to provide enterprise grade functionality, particularly when you are dealing with products designed to be enterprise grade from the ground up, like D2iQ’s Kubernetes platform (DKP) products, like Konvoy, Kommander, and Kaptain. And Kubernetes continues to evolve at a furious pace; the innovative resources of the cloud native community (and those of many vendors) are focused on Kubernetes, not Mesos.
What does this all mean?
The editorial comment for this section goes at the beginning, not the end, because the summary below is now the least accurate part of this blog, due to changes in market and technology realities in the years since it was written. Tools like D2iQ Konvoy and D2iQ Kommander automate and abstract away much of the “get your hands dirty” aspects of working with Kubernetes, while adding the reliability, scalability, and flexibility that was once the exclusive province of Mesos. Indeed, Kubernetes has achieved sufficient capability parity with Mesos that D2iQ (which started life as Mesosphere) is in the process of sunsetting DC/OS, with end-of-life later this year, at the end of October 2021. But the sentiments of the closing paragraph, below, still hold somewhat true: you can make more efficient use of server resources, simplify application portability, and increase developer agility (and thus speed time to market)—and the way to do it now is with Kubernetes.
In summary, all three technologies have something to do with Docker containers and give you access to container orchestration for application portability and scale. So how do you choose between them? It comes down to choosing the right tool for the job (and perhaps even different ones for different jobs). If you are an application developer looking for a modern way to build and package your application, or to accelerate microservices initiatives, the Docker container format and developer tooling is the best way to do so.
If you are a dev/devops team and want to build a system dedicated exclusively to Docker container orchestration, and are willing to get your hands dirty integrating your solution with the underlying infrastructure (or rely on public cloud infrastructure like Google Container Engine or Azure Container Service), Kubernetes is a good technology for you to consider.
If you want to build a reliable platform that runs multiple mission critical workloads including Docker containers, legacy applications (e.g., Java), and distributed data services (e.g., Spark, Kafka, Cassandra, Elastic), and want all of this portable across cloud providers and/or datacenters, then Mesos (or our own Mesos distribution, Mesosphere DC/OS) is the right fit for you.
Whatever you choose, you'll be embracing a set of tools that makes more efficient use of server resources, simplifies application portability, and increases developer agility. You really can't go wrong.
Final editorial comment: we hope this old blog is still providing some value, even in a very different world than the one in which it was written. To find out more about the D2iQ Kubernetes platform, look here.


