






Jun 21, 2017
Edward Hsu
D2iQ

5 min read
It's apparent now that Marc Andreessen's foresight that "software is eating the world" was entirely accurate. And it feels like we are just getting started. Leading business are continuing to fundamentally change how they build and use software to create or extend a competitive edge.
Until the turn of the century, business technology was internally focused (e.g., ERP, CRM), supporting systems of record and business processes. Web 1.0 brought us static web pages, but it's the Web 2.0 era that really changed the world. It created a fundamental shift in how we interact (Facebook), how we share (Flickr, Instagram), how we communicate (Wordpress), how we shop (Magento and the rise of broad-scale eCommerce), and how we learn (Wikipedia). It also enabled businesses to engage customers in ways we never saw before, by enabling user-generated content and exchange of ideas.
Rise of the LAMP Stack
We can thank the rise of broadband and the rush of users for these trends. But, more importantly, we can thank open source software for fueling this wave of innovation. Arguably, we would not have the modern internet we all know and love today were it not for open source.
Any technology stack that enabled the user-generated web had to meet the following requirements: provide a web front-end, store transactional data, produce dynamic web pages and easily manipulate stored data with server-side scripting. All these services need to run on a server operating system.
The "LAMP" stack fit the bill, and freed an entire generation of entrepreneurial hackers to create in a way that we had not seen before.
LAMP is an acronym used to describe an integrated set of software that enabled the creation of dynamic web experiences; consisting of the Linux operating system, Apache's eponymous web server, the MySQL relational database, and PHP as an easily learned scripting language. In addition to being entirely free and open source, they were the right tools at the right time to enable user-generated content and change how digital information is created, shared, and distributed.
And open source is continuing to change how we live, through an entirely new wave of technology; the SMACK stack.
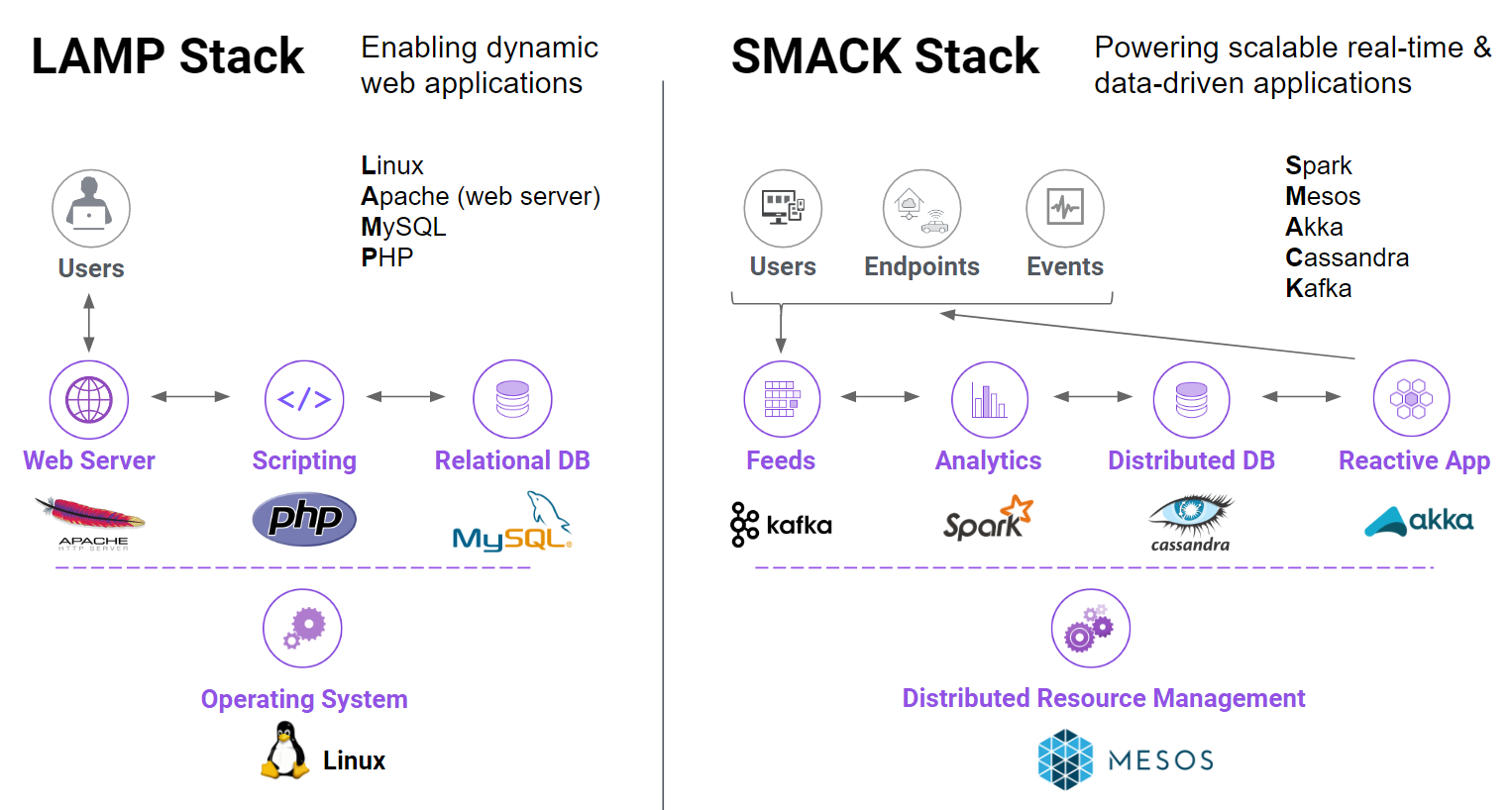
The SMACK Stack Finds its Calling
Today's always-connected era is defined by real-time data at scale and by machine learning. Whether your company sells cars, financial services, jet engines, or t-shirts, the interaction between users and network connected devices (which already outnumber people) are generating vast quantities of data.
Leading businesses are building systems of real-time insights to create new opportunities and deliver new value. Common projects include real-time personalization, anomaly detection, predictive analytics, proactive maintenance and IoT. Unlike "big data" from a decade ago, where data scientists batch process data warehouses to find insights and then recommend ways to capture value, modern fast data applications have real-time big data built-in.
For a technology stack to thrive in this always-connected and data-driven world, it has to meet a new set of requirements: ingest data at scale without loss (this can data streaming from millions of user interactions or IoT sensors), analyze the data in real-time, trigger actions based on the analyzed data, and store the data at cloud-scale. All these services need to run on a distributed and highly resilient cloud-scale operating system.
The SMACK stack is being used for building modern enterprise apps because it performs each of these objectives with a loosely coupled toolchain of technologies that are are all open source, and production-proven at scale.
- Spark - A general engine for large-scale data processing, enabling analytics from SQL queries to machine learning, graph analytics, and stream processing
- Mesos - Distributed systems kernel that provides resourcing and isolation across all the other SMACK stack components. Mesos is the foundation on which other SMACK stack components run.
- Akka - A toolkit and runtime to easily create concurrent and distributed apps that are responsive to messages.
- Cassandra - Distributed database management system that can handle large amounts of data across servers with high availability.
- Kafka - A high throughput, low-latency platform for handling real-time data feeds with no data loss.
The SMACK stack owes its growing momentum to several things. First, most modern enterprise application use cases like IoT, anomaly detection, predictive analytics, and real-time personalization require data processing at scale. Spark, Kafka, Cassandra are some of the most popular cloud-native data services that have been proven to do just that.
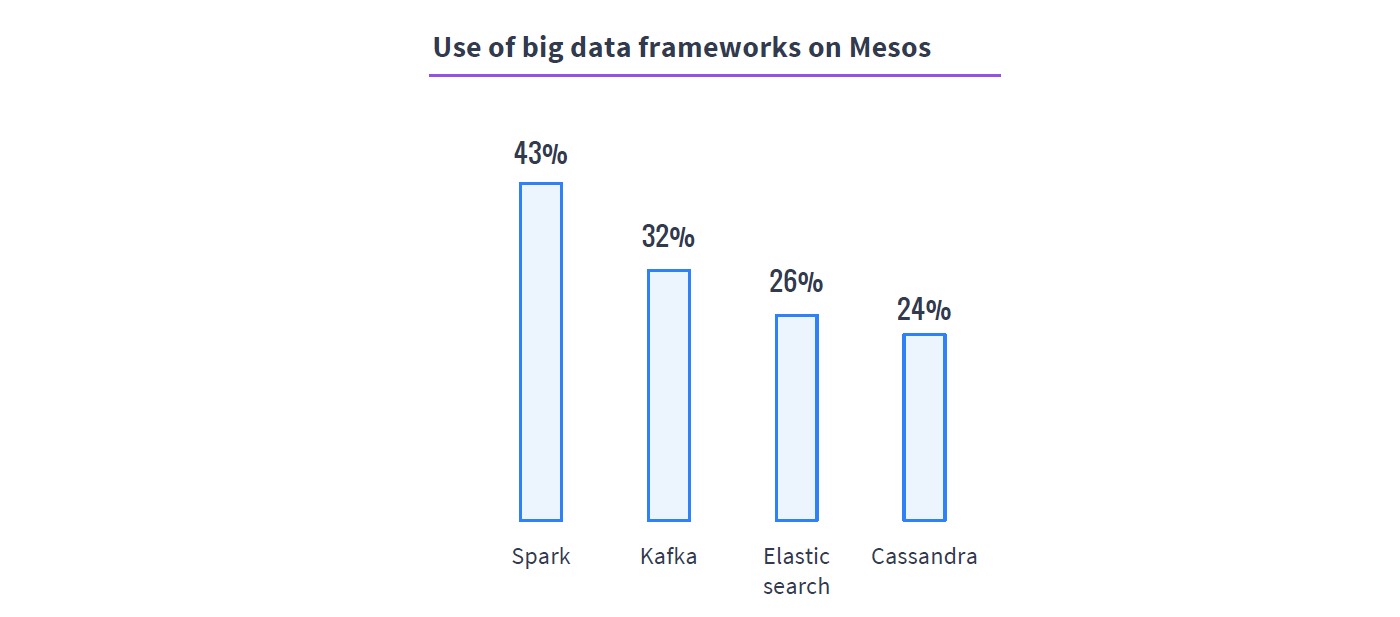
Second, Mesos pools these data services and automates their operations which reduces infrastructure cost and simplifies running the stack. Mesos does this with application-aware scheduling that bifurcates the work to two levels: the upper level is composed of frameworks which encapsulates all the operational requirements of the data services, and the lower level Mesos which offers up shares of the underlying infrastructure. This also means that new data services can be easily adopted over time. A survey of the Mesos community last year showed Spark, Kafka, and Cassandra among the leading frameworks used.
Third, Mesos makes running modern microservices-based applications easier. The same two-level scheduler architecture that pools data services also lets us run container orchestration engines like Marathon. So your containerized app and the backing data services that power them can elastically share the same infrastructure.
The last and increasingly popular reason for the SMACK stack's gaining momentum is that SMACK is agnostic to cloud service providers. For example, if your app relies on AWS platform services like Kinesis for data collection, it will stay with AWS forever. The same application built using Apache Kafka (the "K" in SMACK) instead would have complete hybrid cloud portability - even if you choose to run on AWS infrastructure. This means you can bifurcate the decision of which technology to use, and where to run. You can take your data with you as you migrate between clouds or datacenters.
One additional benefit of using the SMACK stack is your choice of options for adding features or getting support. The LAMP stack had a broad set of commercial champions. The same is true with SMACK today. Each SMACK stack technology has leading commercial entities behind them, that offer enterprise products and support. Examples include Lightbend and Databricks for Spark, DataStax for Cassandra, Confluent for Kafka, and Mesosphere for Mesos. So whether you're already an expert on part of the stack or new to all of SMACK, a broad set of options are available.
What's Next?
Enterprise software is never about rip-and-replace, and services that work will often stick around for decades. The traditional ERP and CRM systems didn't disappear when LAMP came along. The same will be true for the LAMP stack (which has already gone through evolutions) as SMACK continues to gain in popularity and evolve over time. Having Mesos as the underlying layer of the datacenter or cloud, however, means that new distributed systems can be adopted in a relatively straightforward fashion.


